
Assalamu‘alaikum wr. wb.
Halo gais! Neural Network dan Perceptron merupakan salah satu dari Model Machine Learning yang paling penting. Akan tetapi, untuk Neural Network itu lebih ke Deep Learning dalam Bidang AI.

PERCEPTRON
Sumber Materi : Simplilearn.com, Pyimagesearch.com, dan Geeksforgeeks.org
A. Pengertian dan Sejarah Perceptron
Perceptron adalah jenis Neuron Tiruan atau bentuk paling sederhana dari Jaringan Saraf Tiruan. Ini adalah pengklasifikasi biner yang mengambil beberapa input biner dan menghasilkan satu output biner. Perceptron dikembangkan sebagai model matematis dari neuron biologis oleh Frank Rosenblatt pada Tahun 1957.
Perseptron diperkenalkan oleh Frank Rosenblatt pada tahun 1958, sebagai jenis jaringan saraf tiruan yang mampu belajar dan melakukan tugas klasifikasi biner. Rosenblatt adalah seorang psikolog dan ilmuwan komputer yang tertarik untuk mengembangkan mesin yang bisa belajar dan mengenali pola-pola dalam data, terinspirasi oleh cara kerja otak manusia.
Perseptron didasarkan pada konsep unit komputasi sederhana, yang mengambil satu atau lebih input dan menghasilkan satu output, dimodelkan setelah struktur dan fungsi neuron dalam otak. Perseptron dirancang untuk dapat belajar dari contoh-contoh dan menyesuaikan parameter-parameternya untuk meningkatkan akurasinya dalam mengklasifikasikan contoh-contoh baru.
Algoritma perseptron awalnya digunakan untuk memecahkan masalah-masalah sederhana, seperti mengenali karakter tulisan tangan, tetapi segera menghadapi kritik karena kapasitas terbatasnya untuk mempelajari pola-pola kompleks dan ketidakmampuannya untuk menangani data yang tidak dapat dipisahkan secara linear. Keterbatasan-keterbatasan ini menyebabkan penurunan penelitian tentang perceptron pada tahun 1960-an dan 1970-an.
Namun, pada tahun 1980-an, pengembangan backpropagation, algoritma yang kuat untuk melatih jaringan saraf multi-lapis, membangkitkan kembali minat pada jaringan saraf tiruan dan memulai era baru penelitian dan inovasi dalam pembelajaran mesin. Saat ini, perceptron dianggap sebagai bentuk paling sederhana dari jaringan saraf tiruan dan masih banyak digunakan dalam aplikasi seperti pengenalan gambar, pemrosesan bahasa alami, dan pengenalan suara.
Perceptron memiliki batasan dan hanya dapat mempelajari batas keputusan linear. Namun, perceptron berfungsi sebagai dasar untuk arsitektur jaringan saraf yang lebih kompleks. Multilayer Perceptrons (MLP), yang terdiri dari beberapa lapisan perceptron, mampu mempelajari pola non-linear dan merupakan dasar untuk model deep learning.
B. Komponen Utama Perceptron
Sebuah perceptron, unit dasar dari jaringan saraf, terdiri dari komponen-komponen penting yang berkolaborasi dalam pengolahan informasi.
- Fitur Input : Perceptron mengambil beberapa fitur input, setiap fitur input mewakili karakteristik atau atribut dari data input.
- Bobot : Setiap fitur input terkait dengan sebuah bobot, menentukan signifikansi setiap fitur input dalam memengaruhi output perceptron. Selama pelatihan, bobot ini disesuaikan untuk mempelajari nilai-nilai optimal.
- Fungsi Penjumlahan : Perceptron menghitung jumlah tertimbang dari inputnya menggunakan fungsi penjumlahan. Fungsi penjumlahan menggabungkan input dengan bobot mereka masing-masing untuk menghasilkan jumlah tertimbang.
- Fungsi Aktivasi : Jumlah tertimbang kemudian melewati fungsi aktivasi. Perceptron menggunakan fungsi langkah Heaviside, yang mengambil nilai-nilai yang dijumlahkan sebagai input dan membandingkan dengan ambang batas serta memberikan output sebagai 0 atau 1.
- Output : Output akhir dari perceptron ditentukan oleh hasil fungsi aktivasi. Sebagai contoh, dalam masalah klasifikasi biner, output mungkin mewakili kelas yang diprediksi (0 atau 1).
- Bias : Sebuah istilah bias sering dimasukkan dalam model perceptron. Bias memungkinkan model untuk melakukan penyesuaian yang independen dari input. Ini adalah parameter tambahan yang dipelajari selama pelatihan.
- Algoritma Pembelajaran (Aturan Pembaruan Bobot) : Selama pelatihan, perceptron belajar dengan menyesuaikan bobot dan biasnya berdasarkan algoritma pembelajaran. Pendekatan umum adalah algoritma pembelajaran perceptron, yang memperbarui bobot berdasarkan perbedaan antara output yang diprediksi dan output sebenarnya.
Komponen-komponen ini bekerja sama untuk memungkinkan perceptron belajar dan membuat prediksi. Meskipun satu perceptron dapat melakukan klasifikasi biner, tugas-tugas yang lebih kompleks memerlukan penggunaan beberapa perceptron yang diorganisir ke dalam lapisan-lapisan, membentuk jaringan saraf.
1. Fungsi Perceptron
Perceptron adalah suatu fungsi yang memetakan input-nya "x," yang dikalikan dengan koefisien bobot yang telah dipelajari; sebuah nilai output "f(x)" dihasilkan.
Dalam persamaan yang diberikan di atas :
- "w" = vektor dari bobot bernilai riil
- "b" = bias (suatu elemen yang menyesuaikan batas dari pusat tanpa ketergantungan pada nilai input)
- "x" = vektor dari nilai-nilai input x
- "m" = jumlah input ke Perseptron
- Output dapat direpresentasikan sebagai "1" atau "0." Ini juga dapat direpresentasikan sebagai "1" atau "-1" tergantung pada Fungsi Aktivasi yang digunakan.
Mari kita pelajari input dari suatu perceptron pada bagian berikutnya.
2. Input pada Perceptron
Sebuah Perceptron menerima input, mengaturnya dengan nilai bobot tertentu, kemudian menerapkan fungsi transformasi untuk menghasilkan hasil akhir. Gambar di bawah ini menunjukkan sebuah Perceptron dengan keluaran Boolean.
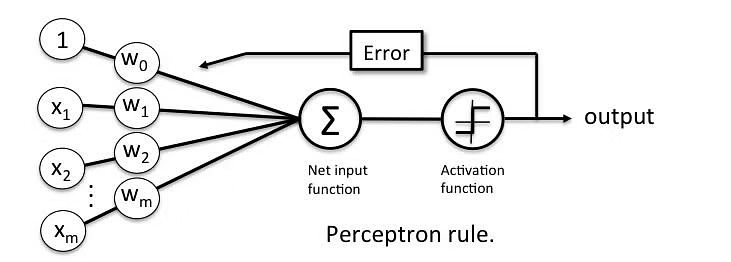
Sebuah keluaran Boolean didasarkan pada input seperti gaji, status menikah, usia, profil kredit masa lalu, dll. Ini hanya memiliki dua nilai: Ya dan Tidak atau Benar dan Salah. Fungsi penjumlahan "∑" mengalikan semua input "x" dengan bobot "w" dan kemudian menjumlahkannya sebagai berikut :
3. Fungsi Aktivasi dalam Perceptron
Fungsi Aktivasi menerapkan aturan langkah (mengubah keluaran numerik menjadi +1 atau -1) untuk memeriksa apakah keluaran dari fungsi penimbangan lebih besar dari nol atau tidak.

Sebagai contoh :
Jika ∑ wixi > 0 => maka keluaran akhir "o" = 1 (menerbitkan pinjaman bank)
Selain itu, keluaran akhir "o" = -1 (menolak pinjaman bank)
Fungsi langkah diaktifkan di atas nilai tertentu dari keluar
4. Output pada Perceptron
Perseptron dengan Keluaran Boolean :
- Input : x1…xn
- Output : o(x1….xn)
AAAAAAAAAAAAAAAA
Bobot : wi => kontribusi input xi terhadap keluaran Perceptron;
w0 => ambang atau ambang batas
Jika ∑w.x > 0, keluaran adalah +1, jika tidak -1. Neuron hanya diaktifkan ketika input terbobot mencapai nilai ambang tertentu.
AAAAAAAAAAAAAAAA
Keluaran +1 menunjukkan bahwa neuron diaktifkan. Keluaran -1 menunjukkan bahwa neuron tidak diaktifkan.
“sgn” merupakan singkatan dari fungsi tanda dengan keluaran +1 atau -1.
5. Fungsi Keputusan (Decision Function)
Fungsi Keputusan φ(z) dari Perceptron didefinisikan untuk mengambil kombinasi linear dari vektor x dan w.

Nilai z dalam fungsi keputusan diberikan oleh :
Fungsi keputusan adalah +1 jika z lebih besar dari ambang θ, dan -1 jika tidak.

Ini adalah algoritma Perceptron.
Bias Unit
Untuk mempermudah, ambang batas θ dapat dibawa ke kiri dan direpresentasikan sebagai w0x0, dengan w0= -θ dan x0= 1.
Nilai w0 disebut satuan bias.
Fungsi keputusan kemudian menjadi :

Output :
Gambar tersebut menunjukkan bagaimana fungsi keputusan menekan wTx menjadi +1 atau -1 dan bagaimana fungsi tersebut dapat digunakan untuk membedakan dua kelas yang dapat dipisahkan secara linier.

C. Arsitektur pada Perceptron
Perceptron adalah salah satu arsitektur Jaringan Saraf Tiruan yang paling sederhana. Ini diperkenalkan oleh Frank Rosenblatt pada tahun 1957. Ini adalah jenis jaringan saraf maju yang paling sederhana, terdiri dari satu lapisan node input yang terhubung sepenuhnya ke lapisan node output. Ini dapat mempelajari pola yang dapat dipisahkan secara linear. Ini menggunakan jenis artificial neuron yang sedikit berbeda yang dikenal sebagai threshold logic units (TLU), yang pertama kali diperkenalkan oleh McCulloch dan Walter Pitts pada tahun 1940-an.
Bobot diberikan untuk setiap node input dari perceptron, menunjukkan signifikansi input tersebut terhadap keluaran. Keluaran perceptron adalah jumlah terbobot dari input yang telah dijalankan melalui fungsi Aktivasi untuk menentukan apakah perceptron akan aktif atau tidak. Ini menghitung jumlah terbobot dari inputnya sebagai :
Fungsi langkah membandingkan jumlah tertimbang ini dengan ambang batas, yang menghasilkan keluaran 1 jika input lebih besar dari nilai ambang batas dan 0 jika tidak, adalah fungsi aktivasi yang paling sering digunakan oleh perceptron. Fungsi langkah paling umum yang digunakan dalam perceptron adalah Fungsi langkah Heaviside :
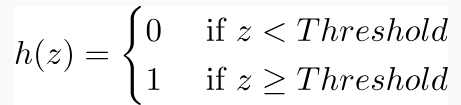
Sebuah perceptron memiliki satu lapisan threshold logic unit dengan setiap TLU terhubung ke semua input.
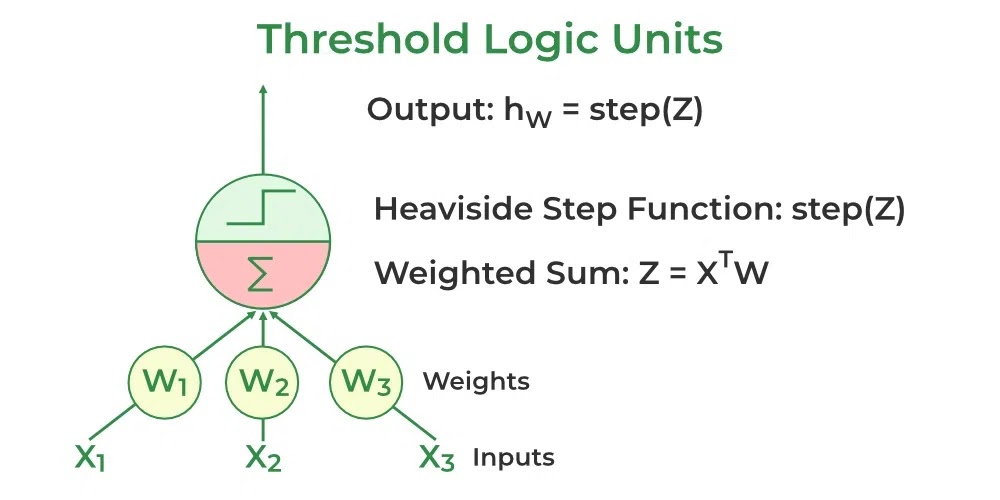 |
| Threshold Logic Units dalam Perceptron |
Ketika semua neuron dalam suatu lapisan terhubung ke setiap neuron dari lapisan sebelumnya, ini dikenal sebagai lapisan sepenuhnya terhubung atau lapisan padat.
Output dari lapisan sepenuhnya terhubung dapat dijelaskan sebagai :
Di mana X adalah input, W adalah bobot untuk setiap neuron input, b adalah bias, dan h adalah fungsi langkah.
Selama pelatihan, bobot perceptron disesuaikan untuk meminimalkan perbedaan antara keluaran yang diprediksi dan keluaran sebenarnya. Biasanya, algoritma pembelajaran terawasi seperti aturan delta atau aturan pembelajaran perceptron digunakan untuk ini.
Di sini, wi,j adalah bobot antara input ke-i dan neuron output ke-j, xi adalah nilai input ke-i, dan yj dan \hat y_j adalah nilai aktual dan nilai yang diprediksi ke-j, \eta adalah tingkat pembelajaran.
D. Penerapan Perceptron dalam Python
1. Bangun Model Perceptron Lapisan Tunggal
Inisialisasi bobot dan kecepatan pembelajaran, Di sini kita mempertimbangkan jumlah nilai bobot input + 1. yaitu +1 untuk bias.
- Tentukan lapisan linier pertama
- Tentukan fungsi aktivasi. Di sini kita menggunakan fungsi Heaviside Step.
- Tentukan Prediksinya
- Tentukan fungsi kerugian.
- Tentukan pelatihan, yang bobot dan biasnya diperbarui sesuai kebutuhan.
- tentukan kesesuaian modelnya.
# Import the necessary libraryimport numpy as np# Build the Perceptron Modelclass Perceptron:def __init__(self, num_inputs, learning_rate=0.01):# Initialize the weight and learning rateself.weights = np.random.rand(num_inputs + 1)self.learning_rate = learning_rate# Define the first linear layerdef linear(self, inputs):Z = inputs @ self.weights[1:].T + + self.weights[0]return Z# Define the Heaviside Step function.def Heaviside_step_fn(self, z):if z >= 0:return 1else:return 0# Define the Predictiondef predict(self, inputs):Z = self.linear(inputs)try:pred = []for z in Z:pred.append(self.Heaviside_step_fn(z))except:return self.Heaviside_step_fn(Z)return pred# Define the Loss functiondef loss(self, prediction, target):loss = (prediction-target)return loss#Define trainingdef train(self, inputs, target):prediction = self.predict(inputs)error = self.loss(prediction, target)self.weights[1:] += self.learning_rate * error * inputsself.weights[0] += self.learning_rate * error# Fit the modeldef fit(self, X, y, num_epochs):for epoch in range(num_epochs):for inputs, target in zip(X, y):self.train(inputs, target)
2. Terapkan model yang ditentukan di atas untuk klasifikasi biner dari Kumpulan Data Kanker Payudara
- impor perpustakaan yang diperlukan
- Muat kumpulan data
- Tetapkan fitur masukan ke x
- Tetapkan fitur target ke y
- Inisialisasi Perceptron dengan jumlah input yang sesuai
- Latih modelnya
- Prediksi dari kumpulan data pengujian
- Temukan keakuratan model
# Import the necessary libraryimport numpy as npfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler# Generate a linearly separable dataset with two classesX, y = make_blobs(n_samples=1000,n_features=2,centers=2,cluster_std=3,random_state=23)# Split the dataset into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=23,shuffle=True)# Scale the input features to have zero mean and unit variancescaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)# Set the random seed legacynp.random.seed(23)# Initialize the Perceptron with the appropriate number of inputsperceptron = Perceptron(num_inputs=X_train.shape[1])# Train the Perceptron on the training dataperceptron.fit(X_train, y_train, num_epochs=100)# Predictionpred = perceptron.predict(X_test)# Test the accuracy of the trained Perceptron on the testing dataaccuracy = np.mean(pred != y_test)print("Accuracy:", accuracy)# Plot the datasetplt.scatter(X_test[:, 0], X_test[:, 1], c=pred)plt.xlabel('Feature 1')plt.ylabel('Feature 2')plt.show()
Output :
NEURAL NETWORK
Sumber Materi : AWS.Amazon.com, Techtarget.com, Investopedia.com, Revou.co, dan Mynextemployee.com
A. Pengertian Neural Network
Sebuah Jaringan Saraf atau Neural Network adalah model Machine Learning (ML) yang dirancang untuk meniru fungsi dan struktur otak manusia. Jaringan saraf adalah jaringan rumit dari simpul-simpul terhubung, atau neuron, yang bekerja sama untuk menangani masalah-masalah yang rumit.
Juga dikenal sebagai jaringan saraf buatan (ANNs) atau jaringan saraf mendalam, jaringan saraf merupakan jenis teknologi pembelajaran mendalam yang diklasifikasikan dalam ranah Kecerdasan Buatan (AI).
Jaringan saraf banyak digunakan dalam berbagai aplikasi, termasuk pengenalan gambar, pemodelan prediktif, dan pemrosesan bahasa alami (NLP). Contoh aplikasi komersial signifikan sejak tahun 2000 melibatkan pengenalan tulisan tangan untuk pemrosesan cek, transkripsi ucapan ke teks, analisis data eksplorasi minyak, prediksi cuaca, dan pengenalan wajah.
B. Sejarah Neural Network
Meskipun konsep mesin terintegrasi yang dapat berpikir telah ada selama berabad-abad, kemajuan terbesar dalam jaringan saraf terjadi dalam 100 tahun terakhir. Pada tahun 1943, Warren McCulloch dan Walter Pitts dari Universitas Illinois dan Universitas Chicago menerbitkan "A Logical Calculus of the Ideas Immanent in Nervous Activity". Penelitian ini menganalisis bagaimana otak dapat menghasilkan pola-pola kompleks dan dapat disederhanakan menjadi struktur logika biner dengan koneksi hanya berupa benar/salah.
Frank Rosenblatt dari Cornell Aeronautical Labratory dikreditkan dengan pengembangan perceptron pada tahun 1958. Penelitiannya memperkenalkan bobot ke karya McCulloch dan Pitt, dan Rosenblatt memanfaatkan karyanya untuk menunjukkan bagaimana komputer dapat menggunakan jaringan saraf untuk mendeteksi gambar dan membuat inferensi.
Setelah periode kekeringan penelitian (sebagian besar karena kekurangan pendanaan) selama tahun 1970-an, Jon Hopfield menyajikan Hopfield Net, sebuah makalah tentang jaringan saraf rekuren pada tahun 1982. Selain itu, konsep backpropagation muncul kembali, dan banyak peneliti mulai memahami potensinya untuk jaringan saraf. Paul Werbos sering dikreditkan dengan kontribusi utama selama periode ini dalam tesis doktornya.
Baru-baru ini, proyek jaringan saraf yang lebih spesifik dibuat untuk tujuan langsung. Sebagai contoh, Deep Blue, yang dikembangkan oleh IBM, mengatasi dunia catur dengan mendorong kemampuan komputer untuk menangani perhitungan kompleks. Meskipun dikenal luas karena mengalahkan juara catur dunia, mesin-mesin jenis ini juga dimanfaatkan untuk menemukan obat baru, mengidentifikasi analisis tren pasar keuangan, dan melakukan perhitungan ilmiah massif.
C. Cara Kerja Neural Network
.png)
Sebuah Jaringan Saraf Buatan atau Neural Network umumnya melibatkan banyak prosesor yang beroperasi secara paralel dan disusun dalam lapisan atau tingkatan. Tingkatan pertama – analog dengan saraf optik dalam pemrosesan visual manusia – menerima informasi input mentah. Setiap tingkatan berikutnya menerima keluaran dari tingkatan sebelumnya daripada input mentah – sama seperti neuron yang lebih jauh dari Saraf optik menerima sinyal dari yang lebih dekat.
Tingkatan terakhir menghasilkan keluaran dari sistem tersebut. Setiap node pemrosesan memiliki domain pengetahuan kecilnya sendiri, termasuk apa yang telah dilihatnya dan aturan-aturan yang awalnya diprogram atau yang dikembangkan olehnya sendiri. Tingkatan tersebut sangat terhubung, yang berarti setiap node di Tingkatan N akan terhubung ke banyak node di Tingkatan N-1 – inputnya – dan di Tingkatan N+1, yang memberikan data input bagi node-node tersebut. Ada satu atau lebih node di lapisan output, dari mana jawaban yang dihasilkannya dapat dibaca.
Neural Network dikenal karena sifat adaptifnya, yang berarti mereka memodifikasi diri saat mereka belajar dari pelatihan awal dan jalankan berikutnya memberikan lebih banyak informasi tentang dunia. Model pembelajaran paling dasar berpusat pada memberi bobot pada aliran input, yaitu bagaimana setiap node mengukur pentingnya data input dari setiap node pendahulunya. Input yang berkontribusi untuk mendapatkan jawaban yang benar diberi bobot lebih tinggi.
D. Jenis-jenis Neural Network

Berikut ini adalah beberapa Jenis dari Neural Network.
1. Feed-Forward Neural Network (FFNN)
Feed-forward Neural Network atau Jaringan saraf maju merupakan salah satu jenis jaringan saraf yang lebih sederhana. Ini menyampaikan informasi dalam satu arah melalui node input; informasi ini terus diproses dalam satu arah ini hingga mencapai node output. Jaringan saraf maju dapat memiliki lapisan tersembunyi untuk fungsionalitas, dan jenis ini paling sering digunakan untuk teknologi pengenalan wajah.
2. Recurrent Neural Network (RNN)
Sebagai jenis jaringan saraf yang lebih kompleks, jaringan saraf rekuren mengambil keluaran dari node pemrosesan dan mentransmisikan informasi kembali ke dalam jaringan. Ini menghasilkan "pembelajaran" teoretis dan peningkatan jaringan. Setiap node menyimpan proses historis, dan proses historis ini digunakan ulang di masa depan selama pemrosesan.
Hal ini menjadi kritis terutama untuk jaringan di mana prediksinya salah; sistem akan berusaha memahami mengapa hasil yang benar terjadi dan menyesuaikan diri secara sesuai. Jenis jaringan saraf ini sering digunakan dalam aplikasi teks ke ucapan.
3. Convolutional Neural Network (CNN)
Convolutional Neural Network atau Jaringan Saraf Konvolusional, juga disebut ConvNets atau CNNs, memiliki beberapa lapisan di mana data diurutkan ke dalam kategori. Jaringan ini memiliki lapisan input, lapisan output, dan banyak lapisan konvolusional tersembunyi di antaranya. Lapisan-lapisan ini menciptakan peta fitur yang mencatat area gambar yang diuraikan lebih lanjut hingga menghasilkan output yang berharga. Lapisan-lapisan ini dapat dipool atau sepenuhnya terhubung, dan jaringan ini sangat bermanfaat untuk aplikasi pengenalan gambar.
Contoh dari CNN untuk Fitur Asisten AI adalah Siri dari Apple, Google Translate, Google Bard, dan Microsoft Copilot.
4. Deconvolutional Neural Network (DNN)
Deconvolutional Neural Network atau Jaringan saraf dekonvolusional bekerja secara terbalik dari jaringan saraf konvolusional. Aplikasi jaringan ini adalah untuk mendeteksi item yang mungkin telah diakui sebagai penting dalam proses eksekusi jaringan saraf konvolusional. Item-item ini kemungkinan besar telah dibuang selama proses eksekusi jaringan saraf konvolusional. Jenis jaringan saraf ini juga banyak digunakan untuk analisis atau pemrosesan gambar.
5. Modular Neural Network (MNN)
Modular Neural Network atau Jaringan Saraf Modular berisi beberapa jaringan yang bekerja secara independen satu sama lain. Jaringan-jaringan ini tidak berinteraksi satu sama lain selama proses analisis. Sebaliknya, proses ini dilakukan untuk memungkinkan proses komputasi yang kompleks dan rumit dilakukan lebih efisien. Serupa dengan industri modular lainnya seperti properti modular, tujuan dari kemandirian jaringan ini adalah agar setiap modul bertanggung jawab atas bagian tertentu dari gambaran besar keseluruhan.
E. Kelebihan dan Kekurangan Neural Network
1. Kelebihan
Jaringan saraf buatan menawarkan berbagai manfaat berikut :
- Kemampuan pemrosesan paralel. Jaringan saraf buatan memiliki kemampuan pemrosesan paralel, yang berarti jaringan dapat menjalankan lebih dari satu tugas pada saat yang bersamaan.
- Penyimpanan informasi. Jaringan saraf buatan menyimpan informasi pada seluruh jaringan, bukan hanya dalam database. Hal ini memastikan bahwa meskipun sejumlah kecil data hilang dari satu lokasi, seluruh jaringan tetap dapat beroperasi.
- Non-linearitas. Kemampuan untuk belajar dan memodelkan hubungan non-linear dan kompleks membantu memodelkan hubungan dunia nyata antara input dan output.
- Toleransi kesalahan. Jaringan saraf buatan memiliki toleransi kesalahan, yang berarti kerusakan atau kesalahan satu atau lebih sel jaringan saraf buatan tidak akan menghentikan penghasilan output.
- Kerusakan bertahap. Ini berarti jaringan secara perlahan mengalami degradasi seiring waktu daripada langsung mengalami degradasi saat terjadi masalah.
- Variabel input tanpa batasan. Tidak ada batasan yang diberlakukan pada variabel input, seperti bagaimana seharusnya didistribusikan.
- Keputusan berdasarkan observasi. Pembelajaran mesin berarti jaringan saraf buatan dapat belajar dari peristiwa dan membuat keputusan berdasarkan observasi.
- Pengolahan data yang tidak teratur. Jaringan saraf buatan sangat baik dalam mengorganisir sejumlah besar data dengan memproses, menyortir, dan mengategorikannya.
- Kemampuan mempelajari hubungan tersembunyi. Jaringan saraf buatan dapat mempelajari hubungan tersembunyi dalam data tanpa memerintahkan hubungan tetap. Ini berarti jaringan saraf buatan dapat lebih baik memodelkan data yang sangat fluktuatif dan variasi yang tidak konstan.
- Kemampuan generalisasi data. Kemampuan untuk menggeneralisasi dan menyimpulkan hubungan yang tidak terlihat pada data yang tidak terlihat berarti jaringan saraf buatan dapat memprediksi output dari data yang tidak terlihat.
2. Kekurangan
Selain manfaat-manfaatnya yang banyak, jaringan saraf juga memiliki beberapa kekurangan, termasuk :
- Kurangnya aturan. Kurangnya aturan untuk menentukan struktur jaringan yang tepat berarti arsitektur jaringan saraf buatan yang sesuai hanya dapat ditemukan melalui uji coba, kesalahan, dan pengalaman.
- Ketergantungan pada perangkat keras. Ketergantungan pada prosesor dengan kemampuan pemrosesan paralel membuat jaringan saraf bergantung pada perangkat keras.
- Terjemahan numerik. Jaringan bekerja dengan informasi numerik, yang berarti semua masalah harus diterjemahkan menjadi nilai numerik sebelum dapat disajikan kepada jaringan saraf buatan.
- Kurangnya kepercayaan. Kurangnya penjelasan di balik solusi yang disajikan adalah salah satu kekurangan terbesar dari jaringan saraf buatan. Ketidakmampuan untuk menjelaskan mengapa atau bagaimana solusi ditemukan menyebabkan kurangnya kepercayaan pada jaringan.
- Hasil yang tidak akurat. Jika tidak dilatih dengan baik, jaringan saraf buatan seringkali dapat menghasilkan hasil yang tidak lengkap atau tidak akurat.
- Sifat kotak hitam. Karena model kecerdasan buatannya yang sifatnya kotak hitam, sulit untuk memahami bagaimana jaringan saraf membuat prediksi atau mengategorikan data.
F. Kegunaan/Penerapan dari Neural Network
Jaringan saraf memiliki berbagai penggunaan yang signifikan di berbagai sektor, di antaranya adalah :
- Diagnosa Medis dengan Klasifikasi Citra Medis : Penggunaan jaringan saraf untuk mengklasifikasi citra medis memungkinkan diagnosa medis yang lebih akurat.
- Pemasaran yang Ditargetkan dengan Pemfilteran Jaringan Sosial dan Analisis Data Perilaku : Jaringan saraf digunakan dalam pemasaran yang ditargetkan dengan menganalisis data perilaku dan memfilter jaringan sosial.
- Prediksi Keuangan dengan Memproses Data Historis dari Instrumen Keuangan : Penerapan jaringan saraf dalam memproses data historis instrumen keuangan membantu dalam prediksi keuangan.
- Prakiraan Beban Listrik dan Permintaan Energi : Jaringan saraf digunakan untuk meramalkan beban listrik dan permintaan energi, membantu dalam manajemen sumber daya.
- Proses dan Kontrol Kualitas : Jaringan Saraf memainkan peran penting dalam proses dan kontrol kualitas di berbagai industri.
- Identifikasi Senyawa Kimia : Aplikasi jaringan saraf termasuk identifikasi senyawa kimia, mempercepat proses analisis kimia.
Dalam konteks ini, kita akan membahas empat aplikasi utama dari Neural Network :
1. Visi Komputer
Penglihatan komputer memungkinkan komputer untuk mengidentifikasi dan memahami gambar dan video. Aplikasi mencakup pengenalan visual pada mobil otomatis dan moderasi konten.
2. Pengenalan Suara
Jaringan saraf digunakan untuk menganalisis ucapan manusia, memfasilitasi asisten virtual dan transkripsi otomatis.
3. Pemrosesan Bahasa Alami (NLP)
NLP menggunakan jaringan saraf untuk memproses teks alami, seperti chatbot, analisis teks, dan pembuatan ringkasan dokumen.
4. Mesin Rekomendasi
Jaringan saraf digunakan dalam pelacakan aktivitas pengguna untuk menghasilkan rekomendasi yang dipersonalisasi, memperbaiki pengalaman pengguna.
Dengan demikian, jaringan saraf memiliki dampak besar di berbagai sektor dengan menghadirkan solusi cerdas dan otomatisasi berbasis data.
G. Kegunaan/Penerapan dari Neural Network
Sumber Materi : Pyimagesearch.com, Geeksforgeeks.org, dan ChatGPT
Kode program berikut ini adalah implementasi sederhana dari sebuah model neural network menggunakan TensorFlow. Tujuannya adalah untuk melatih model untuk mempelajari Hubungan Linier antara suatu input (xs) dan output (ys) dengan menggunakan model linear sederhana.
Model yang didefinisikan di sini adalah model sequential dengan satu lapisan Dense (fully connected layer) yang memiliki satu unit dan input shape sebesar satu. Ini adalah model linier sederhana. Setelah itu, mengkompilasi model dengan menggunakan Stochastic Gradient Descent (SGD) sebagai optimizer dan Mean Squared Error (MSE) sebagai fungsi loss. Tujuan pelatihan adalah untuk meminimalkan nilai MSE.
Selanjutnya, Data yang digunakan untuk pelatihan terdiri dari pasangan input (xs) dan output (ys). Dalam hal ini, hubungan antara input dan output adalah y = 2x - 1. Jika sudah, Proses pelatihan dilakukan dengan memanggil metode fit pada model. Model akan mempelajari hubungan antara input dan output melalui proses iteratif selama 100 epoch. Setelah model dilatih, kita dapat menggunakannya untuk membuat prediksi untuk nilai baru. Dalam hal ini, kita mencetak prediksi untuk nilai input 10.0.
Terakhir, Bobot yang telah dipelajari oleh model dapat diakses dan dicetak. Dalam hal ini, kita mencetak bobot yang digunakan oleh lapisan Dense. Bobot ini akan mendekati nilai 2 dan -1 sesuai dengan hubungan linear yang diinginkan.
import tensorflow as tfimport numpy as npfrom tensorflow.keras import Sequentialfrom tensorflow.keras.layers import Dense# Define the modelmodel = Sequential([Dense(units=1, input_shape=[1])])model.compile(optimizer='sgd', loss='mean_squared_error')# Input dataxs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)# Train the modelmodel.fit(xs, ys, epochs=100)# Print the prediction for a new valueprint(model.predict([10.0]))# Print the learned weightsprint("Here are the weights: {}".format(model.get_weights()))
Output :
Epoch 1/100 1/1 [==============================] - 0s 449ms/step - loss: 0.5658 Epoch 2/100 1/1 [==============================] - 0s 10ms/step - loss: 0.5539 Epoch 3/100 1/1 [==============================] - 0s 9ms/step - loss: 0.5423 Epoch 4/100 1/1 [==============================] - 0s 10ms/step - loss: 0.5310 Epoch 5/100 1/1 [==============================] - 0s 8ms/step - loss: 0.5200 Epoch 6/100 1/1 [==============================] - 0s 12ms/step - loss: 0.5092 Epoch 7/100 1/1 [==============================] - 0s 10ms/step - loss: 0.4987 Epoch 8/100 1/1 [==============================] - 0s 9ms/step - loss: 0.4883 Epoch 9/100 1/1 [==============================] - 0s 9ms/step - loss: 0.4783 Epoch 10/100 1/1 [==============================] - 0s 8ms/step - loss: 0.4684 :::::::::::::::::::::::::::::::::::: :::::::::::::::::::::::::::::::::::: :::::::::::::::::::::::::::::::::::: Epoch 91/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0872 Epoch 92/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0854 Epoch 93/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0836 Epoch 94/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0819 Epoch 95/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0802 Epoch 96/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0786 Epoch 97/100 1/1 [==============================] - 0s 10ms/step - loss: 0.0770 Epoch 98/100 1/1 [==============================] - 0s 9ms/step - loss: 0.0754 Epoch 99/100 1/1 [==============================] - 0s 13ms/step - loss: 0.0738 Epoch 100/100 1/1 [==============================] - 0s 8ms/step - loss: 0.0723 1/1 [==============================] - 0s 93ms/step [[18.215405]] Here are the weights: [array([[1.886285]], dtype=float32), array([-0.6474466], dtype=float32)]
Kemudian, kita melakukan Implementasi dari Dataset Fashion MNIST dengan TensorFlow. Fashion MNIST adalah kumpulan data citra yang sering digunakan dalam pembelajaran mesin dan pembelajaran mendalam untuk menggantikan dataset MNIST yang lebih Tradisional.
import tensorflow as tfdata = tf.keras.datasets.fashion_mnist(training_images, training_labels), (test_images, test_labels) = data.load_data()training_images = training_images / 255.0test_images = test_images / 255.0
Output :
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/step
Selanjutnya, kita akan membuat pembuatan, kompilasi, dan pelatihan model neural network menggunakan TensorFlow untuk dataset Fashion MNIST.
model = tf.keras.models. Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation=tf.nn.relu),tf.keras.layers.Dense(10, activation=tf.nn.softmax)])model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(training_images, training_labels, epochs=5)
Output :
Epoch 1/5
1875/1875 [==============================] - 10s 4ms/step - loss: 0.4992 - accuracy: 0.8229
Epoch 2/5
1875/1875 [==============================] - 8s 5ms/step - loss: 0.3779 - accuracy: 0.8634
Epoch 3/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.3381 - accuracy: 0.8763
Epoch 4/5
1875/1875 [==============================] - 7s 4ms/step - loss: 0.3140 - accuracy: 0.8847
Epoch 5/5
1875/1875 [==============================] - 9s 5ms/step - loss: 0.2948 - accuracy: 0.8916
<keras.src.callbacks.History at 0x79618074bbb0>Pada Hasil Output di atas, meskipun hanya 5 Epoch saja tapi sedikit Lama.
Berikutnya, kita akan melakukan prediksi menggunakan model yang sudah dilatih pada data uji dan kemudian membandingkan prediksi dengan label sebenarnya.
classifications = model.predict(test_images)print(classifications[0])print(test_labels[0])
Output :
313/313 [==============================] - 1s 2ms/step
[1.2080648e-05 1.9276634e-09 2.5639690e-07 1.5074297e-08 6.2841686e-08
1.0380006e-03 7.3418109e-06 8.1390277e-02 1.0447214e-05 9.1754144e-01]
9Kemudian, Kode Program ini menggambarkan pembuatan dan arsitektur sebuah model neural network yang lebih kompleks menggunakan TensorFlow, khususnya untuk dataset Fashion MNIST.
import tensorflow as tfdata = tf.keras.datasets.fashion_mnist(training_images, training_labels), (test_images, test_labels) = data.load_data()training_images = training_images / 255.0test_images = test_images / 255.0model = tf.keras.models.Sequential([tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(128, activation=tf.nn.relu),tf.keras.layers.Dense(10, activation=tf.nn.softmax)])model.summary()
Output :
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 64) 640
max_pooling2d (MaxPooling2 (None, 13, 13, 64) 0
D)
conv2d_1 (Conv2D) (None, 11, 11, 64) 36928
max_pooling2d_1 (MaxPoolin (None, 5, 5, 64) 0
g2D)
flatten_1 (Flatten) (None, 1600) 0
dense_3 (Dense) (None, 128) 204928
dense_4 (Dense) (None, 10) 1290
=================================================================
Total params: 243786 (952.29 KB)
Trainable params: 243786 (952.29 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________Kode program ini melibatkan dua langkah penting dalam pelatihan model Neural Network menggunakan TensorFlow: kompilasi dan pelatihan.
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(training_images, training_labels, epochs=5)
Output :
Epoch 1/5
1875/1875 [==============================] - 94s 49ms/step - loss: 0.4388 - accuracy: 0.8390
Epoch 2/5
1875/1875 [==============================] - 92s 49ms/step - loss: 0.2917 - accuracy: 0.8931
Epoch 3/5
1875/1875 [==============================] - 90s 48ms/step - loss: 0.2480 - accuracy: 0.9087
Epoch 4/5
1875/1875 [==============================] - 90s 48ms/step - loss: 0.2138 - accuracy: 0.9197
Epoch 5/5
1875/1875 [==============================] - 89s 47ms/step - loss: 0.1886 - accuracy: 0.9301Kode program ini melibatkan 3 Langkah utama, yaitu :
- Kompilasi dan Pelatihan Model
- Evaluasi Model pada Data Uji
- Prediksi dan Pembandingan dengan Label Sebenarnya
Berikut ini adalah Kode Programnya :
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])model.fit(training_images, training_labels, epochs=5)model.evaluate(test_images, test_labels)classifications = model.predict(test_images)print(classifications[0])print(test_labels[0])
Output :
Epoch 1/5
1875/1875 [==============================] - 98s 52ms/step - loss: 0.1660 - accuracy: 0.9371
Epoch 2/5
1875/1875 [==============================] - 91s 49ms/step - loss: 0.1455 - accuracy: 0.9463
Epoch 3/5
1875/1875 [==============================] - 91s 49ms/step - loss: 0.1272 - accuracy: 0.9513
Epoch 4/5
1875/1875 [==============================] - 91s 49ms/step - loss: 0.1116 - accuracy: 0.9570
Epoch 5/5
1875/1875 [==============================] - 94s 50ms/step - loss: 0.0963 - accuracy: 0.9633
313/313 [==============================] - 4s 12ms/step - loss: 0.3010 - accuracy: 0.9124
313/313 [==============================] - 5s 15ms/step
[3.7595530e-12 5.0182789e-14 1.8197351e-13 1.5694413e-11 1.6663398e-11
1.8060793e-10 1.0701293e-11 8.0059003e-08 2.3352181e-13 9.9999982e-01]Untuk membaca Artikel sebelumnya tentang Deep Learning, silakan lihat di sini.
Untuk melihat dan menyimulasikan Neural Network, silakan lihat dan klik di sini (Playground Neural Network). Dan jika ingin menyimulasikan Convolution Neural Network (CNN), silakan lihat di sini (CNN Explainer).
Mohon maaf apabila ada kesalahan apapun.
Terima Kasih 😄😘👌👍 :)
Wassalamu‘alaikum wr. wb.