
Assalamu‘alaikum wr. wb.
Dalam Big Data, Hadoop merupakan salah satu Software untuk yang digunakan untuk menyimpan dan memproses Data yang sangat Besar. Hadoop juga merupakan Framework yang dikembangkan oleh Apache untuk keperluan Big Data. Kali ini, kita akan menjelaskan tentang Apa itu Apache Hadoop dan Cara mengistalnya.

PENGERTIAN
Sumber Artikel : AWS.Amazon.com, Dqlab.id, Glints.com, Data.LAN.go.id
A. Pengertian dan Sejarah Hadoop
Hadoop, atau secara resmi dikenal sebagai Apache Hadoop, merupakan salah satu implementasi dari teknologi Big Data. Ini bukan hanya sekadar perangkat lunak, tetapi juga sebuah kerangka kerja yang dapat diakses secara terbuka atau open source. Secara sederhana, Hadoop adalah kumpulan perangkat lunak yang dirancang untuk mengatasi permasalahan yang melibatkan jumlah data yang besar.
Dengan jumlah data yang terus berkembang di era internet saat ini, Hadoop menjadi solusi yang relevan untuk menyimpan dan mengelola data dalam skala besar. Dengan volume data yang besar dan berbagai variasi data yang dihasilkan oleh perusahaan, serta kebutuhan akan akses data yang cepat, Hadoop diharapkan dapat mengatasi tantangan-tantangan ini.
Ada tiga prinsip penting yang terkait dengan Hadoop. Pertama, kemampuannya untuk menggabungkan banyak komputer menjadi satu kesatuan, sehingga data dapat didistribusikan di seluruh jaringan untuk memastikan keamanan data. Kedua, Hadoop memiliki sistem yang membagi proses komputasi menjadi bagian-bagian yang lebih kecil untuk meningkatkan efisiensi, menggunakan teknik yang dikenal sebagai map reduce yang dikoordinasikan oleh Job Tracker. Dan yang terakhir, sistem Hadoop dapat mendistribusikan beban penyimpanan di antara berbagai komputer untuk mengamankan data jika salah satu komputer mengalami kegagalan. Sistem ini dikenal dengan sebutan Hadoop Distributed File System (HDFS).
Hadoop terinspirasi dari paper Google File System (GFS) yang diterbitkan pada Oktober 2003. Paper ini memberikan gambaran tentang bagaimana Google menangani Big Data untuk menyimpan data besar miliknya. Pada Tahun 2005, Doug Cutting dan Mike Cafarella mulai mengembangkan Hadoop ketika mereka bekerja di Yahoo!. Perbedaan utama antara Google File System (GFS) dan Hadoop adalah dalam sifatnya sebagai closed source dan open source.
B. Jenis-jenis Ekosistem Hadoop
 |
| Ekosistem Hadoop |
Selama beberapa tahun terakhir, ekosistem Hadoop telah berkembang secara signifikan karena kemampuannya untuk dikembangkan. Saat ini, ekosistem Hadoop mencakup berbagai alat dan aplikasi yang membantu dalam pengumpulan, penyimpanan, pemrosesan, analisis, dan manajemen big data. Beberapa aplikasi yang paling terkenal dan banyak digunakan adalah :
1. Apache Spark
Sebuah sistem pemrosesan terdistribusi sumber terbuka yang biasanya digunakan untuk menangani beban kerja Big Data. Apache Spark menggunakan teknik caching dalam memori dan eksekusi yang dioptimalkan untuk memastikan performa yang cepat. Selain itu, Apache Spark mendukung berbagai tugas seperti pemrosesan batch, analitik streaming, pembelajaran mesin, basis data grafik, dan kueri ad hoc.
2. Presto
Sebuah mesin kueri SQL terdistribusi sumber terbuka yang dioptimalkan untuk analisis data ad-hoc dengan latensi yang rendah. Presto mendukung standar ANSI SQL, termasuk kueri, agregasi, penggabungan, dan fungsi jendela yang kompleks. Presto juga mampu memproses data dari berbagai sumber, termasuk Hadoop Distributed File System (HDFS) dan Amazon S3.
3. Hive
Sebuah platform yang memungkinkan pengguna untuk menggunakan Hadoop MapReduce melalui antarmuka SQL. Hal ini memungkinkan analisis data pada skala besar, serta penyimpanan data terdistribusi dan toleran terhadap kesalahan.
4. HBase
Sebuah basis data non-relasional sumber terbuka yang berjalan di atas Hadoop Distributed File System (HDFS) atau Amazon S3 (dengan menggunakan EMRFS). HBase adalah penyimpanan big data yang dapat diskalakan secara masif dan terdistribusi, dirancang untuk akses acak yang konsisten dan real-time pada tabel dengan miliaran baris dan jutaan kolom.
5. Zeppelin
Sebuah notebook interaktif yang memungkinkan eksplorasi data secara interaktif, memfasilitasi kerja kolaboratif dan pemahaman yang lebih baik tentang data.
C. Jenis-jenis Modul Hadoop
Hadoop terdiri dari beberapa modul utama yang membentuk fondasi bagi sistemnya :
1. Hadoop Distributed File System (HDFS)
Ini adalah sistem file terdistribusi yang dirancang untuk berjalan pada perangkat keras standar atau kelas bawah. HDFS menawarkan throughput data yang lebih tinggi daripada sistem file tradisional, serta tingkat toleransi kesalahan yang tinggi dan dukungan native untuk set data besar.
2. Yet Another Resource Negotiator (YARN)
YARN bertanggung jawab untuk mengelola dan memantau simpul klaster serta penggunaan sumber daya. YARN mengatur penjadwalan pekerjaan dan tugas, memastikan sumber daya digunakan secara efisien.
3. MapReduce
Ini adalah kerangka kerja yang membantu program melakukan komputasi paralel pada data. Dalam prosesnya, tugas peta mengambil data input dan mengonversinya menjadi set data yang dapat dikomputasi dalam pasangan nilai kunci. Output dari tugas peta kemudian digunakan oleh tugas reduksi untuk melakukan agregasi dan menghasilkan output yang diinginkan.
4. Hadoop Common
Modul ini menyediakan pustaka Java umum yang dapat digunakan di semua modul Hadoop. Ini mencakup fungsionalitas yang penting bagi operasi dasar sistem, serta memfasilitasi integrasi antar-modul.
5. Pig
Dalam tutorial Hadoop, Pig adalah platform skrip terdepan untuk memproses dan menganalisis Big Data. Pig dapat menggunakan data terstruktur dan tidak terstruktur untuk mendapatkan wawasan yang dapat ditindaklanjuti dan kemudian menyimpan hasilnya di HDFS. Pig memiliki dua komponen penting; pertama, bahasa skrip Pig Latin bersama dengan mesin runtime untuk memproses dan menganalisis program MapReduce. Pig beroperasi dalam tiga tahap: pertama dengan memuat data dan menulis skrip, kemudian operasi Pig, dan akhirnya eksekusi rencana. Pig mendukung model data sebagai Atom, Tuple, Bag, dan peta dalam berbagai bentuk.
6. Hive
Sebagai perangkat lunak gudang data, Hive menggunakan bahasa mirip SQL, HiveQL, untuk melakukan kueri melalui basis data terdistribusi. Ada dua jenis data utama di Hive; pertama, tipe data Primitif dengan data numerik, string, tanggal/waktu, dan data berbagai macam lainnya, dan yang kedua adalah tipe data Kompleks yang mencakup array, peta, struct, dan unit. Hive memiliki dua mode berbeda yaitu Mode Lokal dan Mode Mapreduce. Arsitektur Hive pertama-tama melakukan kompilasi untuk pemeriksaan dan analisis, kemudian mengoptimalkan dengan tugas dan eksekutor MapReduce dan HDFS untuk menyelesaikan kueri. Dalam bagian tutorial Hadoop ini, pemodelan data Hive terdiri dari Tabel, Partisi, dan Bucket.
7. HBase
Dimodelkan berdasarkan Bigtable milik Google, HBase adalah sistem penyimpanan lengkap yang dibangun dengan tujuan utama mengelola miliaran baris dan jutaan kolom pada perangkat keras komunitas. HBase memungkinkan data disimpan dalam bentuk tabel, sehingga sangat memudahkan untuk pembacaan dan penulisan cepat. HBase tidak menggunakan skema tetap dan dapat bekerja dengan aliran data terstruktur maupun semi-terstruktur. Regions dan Zookers adalah dua komponen arsitektur utama HBase. HBase telah diimplementasikan di beberapa organisasi global, termasuk Yahoo, Twitter, Facebook, dan Adobe.
8. Sqoop
Sqoop berfungsi sebagai alat atau media untuk memuat data dari sistem manajemen basis data relasional (RDBMS) eksternal ke sistem Hadoop dan kemudian mengekspornya kembali ke RDBMS. Sqoop dilengkapi dengan fitur eksklusif seperti impor/ekspor paralel, impor hasil kueri SQL, konektor di antara RDBMS, integrasi keamanan Kerberos, dan mendukung beban tambahan serta penuh. Arsitektur Sqoop menawarkan kemudahan impor dan ekspor menggunakan perintah dan cukup mudah diimplementasikan.
D. Jenis-jenis Instalasi Hadoop
Aslinya, Hadoop dirancang untuk beroperasi di sistem operasi Unix atau Linux. Namun, meskipun tidak dianjurkan, ia juga dapat diimplementasikan pada perangkat berbasis Windows.
Selain itu, teknologi ini memiliki berbagai jenis instalasi dengan metode dan proses kerja yang berbeda. Hal ini memungkinkan data scientist untuk memilih instalasi yang sesuai dengan kebutuhan mereka.
Berikut adalah daftar dan penjelasan mengenai berbagai jenis instalasi Hadoop, yang dikutip dari C-Sharp Corner.
1. Standalone mode
Ini adalah bentuk paling sederhana dari mode Hadoop yang berjalan pada satu node atau sistem.
Pada mode ini, terdapat proses JVM tunggal yang digunakan untuk mensimulasikan sistem terdistribusi. Mode ini menggunakan sistem file lokal untuk penyimpanan.
HDFS tidak aktif di mesin berbasis standalone mode dan semua operasi file dilakukan di mesin lokal dengan tambahan HDFS – YARN. Kedua komponen ini tidak didukung dalam mode ini.
Biasanya, mode standalone digunakan untuk menguji pekerjaan berbasis program MapReduce sebelum dijalankan di cluster.
2. Pseudo-distributed mode
Jika ingin mensimulasikan cluster sebenarnya, data scientist dapat menggunakan pseudo-distributed mode instalasi Hadoop.
Mode ini menggabungkan kualitas dari mode standalone dan cluster fully-distributed.
Mode ini berjalan pada satu node, namun memiliki dua proses JVM untuk mensimulasikan dua node, satu sebagai master dan satu lagi untuk menangani pekerjaan.
HDFS digunakan untuk penyimpanan data dan YARN digunakan untuk mengelola sumber daya di instalasi Hadoop.
Biasanya, mode ini digunakan untuk pengujian lingkungan yang lengkap dan direkomendasikan untuk keperluan lain dengan konfigurasi kerja yang serupa.
3. Fully-distributed mode
Jenis instalasi Hadoop terakhir yang dapat dimanfaatkan oleh para scientist adalah fully-distributed mode.
Mode ini adalah lingkungan produksi yang berjalan pada sekelompok mesin terdistribusi yang berfungsi untuk traffic pengguna.
Jenis instalasi ini sangat penting, di mana beberapa node digunakan dan beberapa di antaranya menjalankan Daemon Master, seperti Namenode dan Resource Manager.
Node lainnya menjalankan Daemon Slave, seperti DataNode dan Node Manager.
TUTORIAL
Sumber Tutorial : Javatpoint.com, Simplilearn.com, Kontext.tech, Medium.com (@DataEngineeer), dan Gamelab.id
Berikut ini, beberapa Langkah untuk melakukan Instalasi Hadoop, khususnya untuk di Windows.
A. Cara Download dan Instalasi Hadoop
1. Download dan Ekstrak Folder Hadoop
Pertama, bukalah Situs Resmi dari Apache Hadoop di sini (https://hadoop.apache.org). Lalu, klik pada "binary".


Setelah itu, Ekstrak File Hadoop ke File Explorer, lalu pindahkan ke Disc/Drive C.
.jpg)
A
2. Edit Konfigurasi
Jika sudah selesai, maka yang harus Anda lakukan adalah mengatur dan mengedit pada bagian System Environment Variables yang ada di Komputer Windows.
Kemudian, tambahkan :
- Variable Name : HADOOP_HOME
- Variable Value : C:\hadoop\bin
Setelah itu, klik "Ok".
.jpg)
Kemudian, kita atur dengan mengeklik "Environment Variables...", cari di bagian Path lalu klik "Edit...", lalu klik di Tombol "New" dan tempelkan Alamat Folder Flutter tadi. Setelah itu, klik di Tombol "OK" semuanya.

3. Download Java JDK
Jika belum mempunyai Java, maka Download terlebih dahulu Java JDK di sini. Karena, Hadoop tidak bisa berjalan tanpa Java.

4. Memeriksa Versi Hadoop
Kemudian, periksalah Versi Hadoop yang Anda gunakan dengan mengetik :
hadoop version

5. Menambahkan Kode Konfigurasi pada File di Hadoop
Jika sudah selesai Langkah-langkah di atas, maka bukalah File Explorer dan arahkan ke :
C:\hadoop\etc\hadoop
.jpg)
Dan kemudian, bukalah File core-site.xml, dan tambahkanlah di dalam Tag <configuration> :
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>Dengan menggunakan nama fs.defaultFS dan Port yang terletak di hdfs://localhost:9000.

Setelah itu, bukalah File hdfs-site.xml di Folder yang sama seperti yang ada di atas. Kemudian, isilah pada Tag Konfigurasi <configuration> dengan data yang sama seperti di atas.
.jpg)
6. Membuat Folder baru di Hadoop
Jika sudah, maka kembalilah ke Folder Hadoop (Lihatlah Petunjuk di bawah ini), dan buatlah Folder "data".
C:\hadoop

Kemudian, masuklah ke dalam Folder "data" dan buatlah 2 Folder baru yang bernama "namenode" dan "datanode".
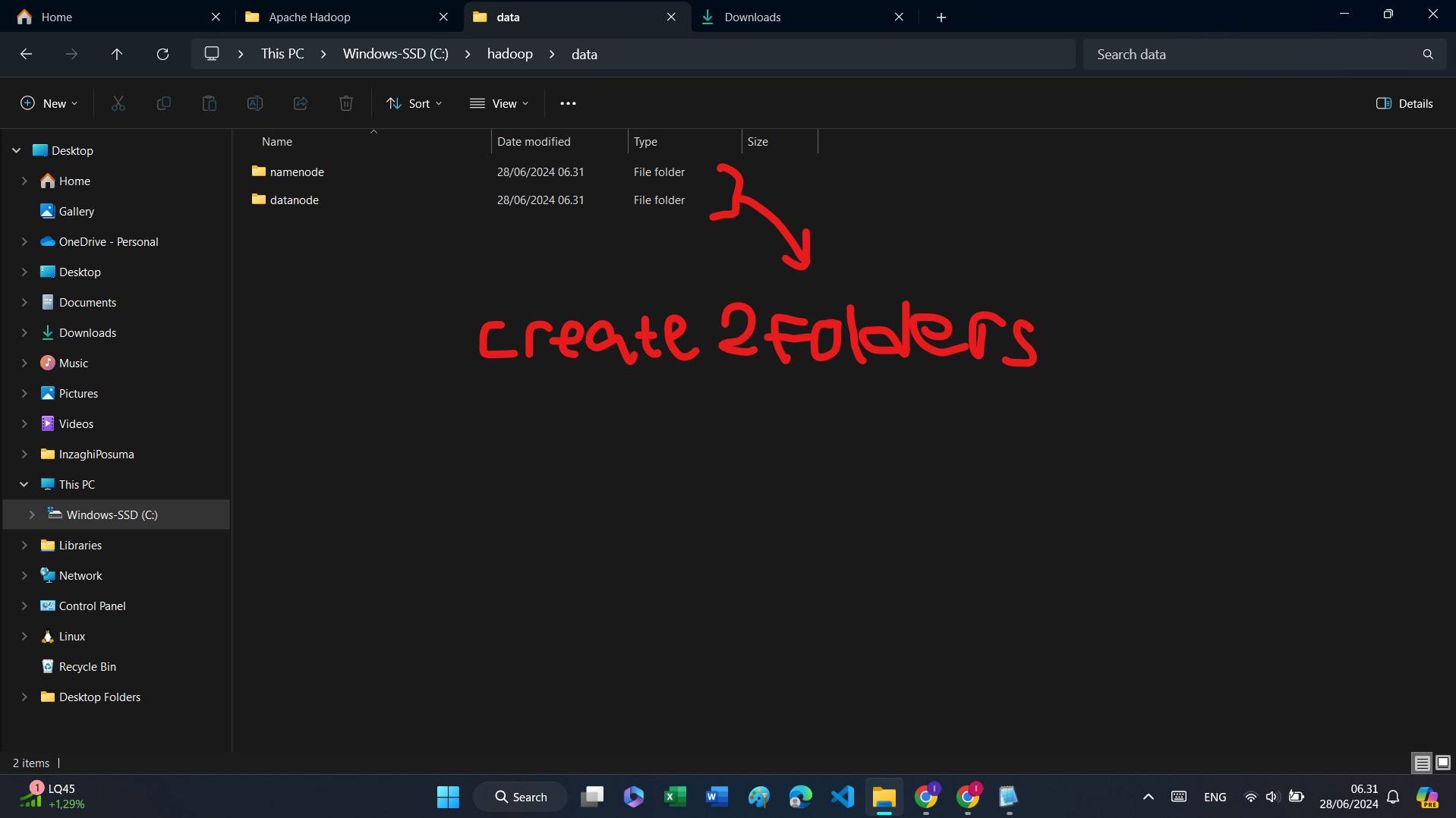
7. Meakukan Konfiguasi ke beberapa File
Anda harus mengkonfigurasi Hadoop pada fase ini dengan memodifikasi beberapa file konfigurasi. Arahkan ke folder "etc/hadoop" di dalam folder Hadoop. Anda harus melakukan perubahan pada 4 File berikut :
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
a. hdfs-site.xml
Untuk core-site.xml, sudah dilakukan di atas, dan selanjutnya kita tambahkan lagi beberapa Kode pada File hdfs-site.xml :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>C:\hadoop\data\datanode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>C:\hadoop\data\namenode</value>
</property>
</configuration>Ubahlah ssuai dengan Letak Folder di Komputer kamu ya!
b. mapred-site.xml
Jika sudah, maka tambahkan pada File mapred-site.xml yang terletak di C:\hadoop\etc\hadoop berikut ini :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>
Di atas berlaku jika kalian ingin menjalankan MapReduce dan HDFS sekaligus.
c. yarn-site.xml
Setelah itu, tambahkan beberapa Kode pada File yarn-site.xml yang terletak di Folder yang sama seperti di atas, yaitu Folder Hadoop.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
8. Melengkapi pada Folder bin
Dikarenakan jika kita cek pada File bin, Tidak ditemukan File winutils.exe, sehingga Tidak bisa menjalankan HDFS. Yang harus Anda lakukan adalah melakukan Download File bin di Google Drive berikut ini, dan letakkan pada Folder dengan cara mengekstraknya ke sini :
C:\hadoop\bin

Sehigga akan menjadi seperti ini :

Jika kita klik File winutils.exe sudah bisa dibuka, artinya kita sudah bisa menjalankan HDFS, dan lakukan Instruksi seeanjutnya.
9. Inisialisasi Hadoop HDFS
Jika sudah, maka ketiklah Perintah ini di Command Prompt (CMD) dan Jalankan sebagai Administrator :
hdfs namenode -format

Setelah itu, ktiklah "Y" jika kalian ditanya seperti ini, untuk melakukan Reformating pada Folder datanode :
Re-format filesystem in Storage Directory root= C:\hadoop\data\datanode; location= null ? (Y or N) Y
.jpg)
Anda telah Berhasil jika sudah tertulis :
INFO common.Storage: Storage directory C:\hadoop\data\datanode has been successfully formatted.
Jika masih belum berhasil membuka Hadoop dengan Localhost, silakan lihat di sini (Stackoverflow.com). Lalu, ketiklah Peintah berikut ini di dalam Folder C:\hadoop\sbin :
stop-all.cmd hdfs datanode -format hdfs namenode -format start-all.cmd
.jpg)
Kemudian, ketiklah lagi :
jps
Maka, hasilnya :
.jpg)
B. Membuat File MapReduce di Hadoop
VIDEO
Untuk melihat Tutorial lainnya dan lebih jelasnya tentang Instalasi dan Penggunaan Apache Hadoop, silakan lihat Video-video YouTube di bawah ini.
1. Instalasi Hadoop di Windows
2. Big Data dengan Hadoop
Itulah Penjelasan dan Tutorial Cara Install dan menggunakan Hadoop untk Big Data.
Terima Kasih 😄😘👌👍 :)
Wassalamu‘alaikum wr. wb.